🦉 OWL: Probing Cross-Lingual Recall of Memorized Texts via World Literature

 Code
Code
 Paper
Paper
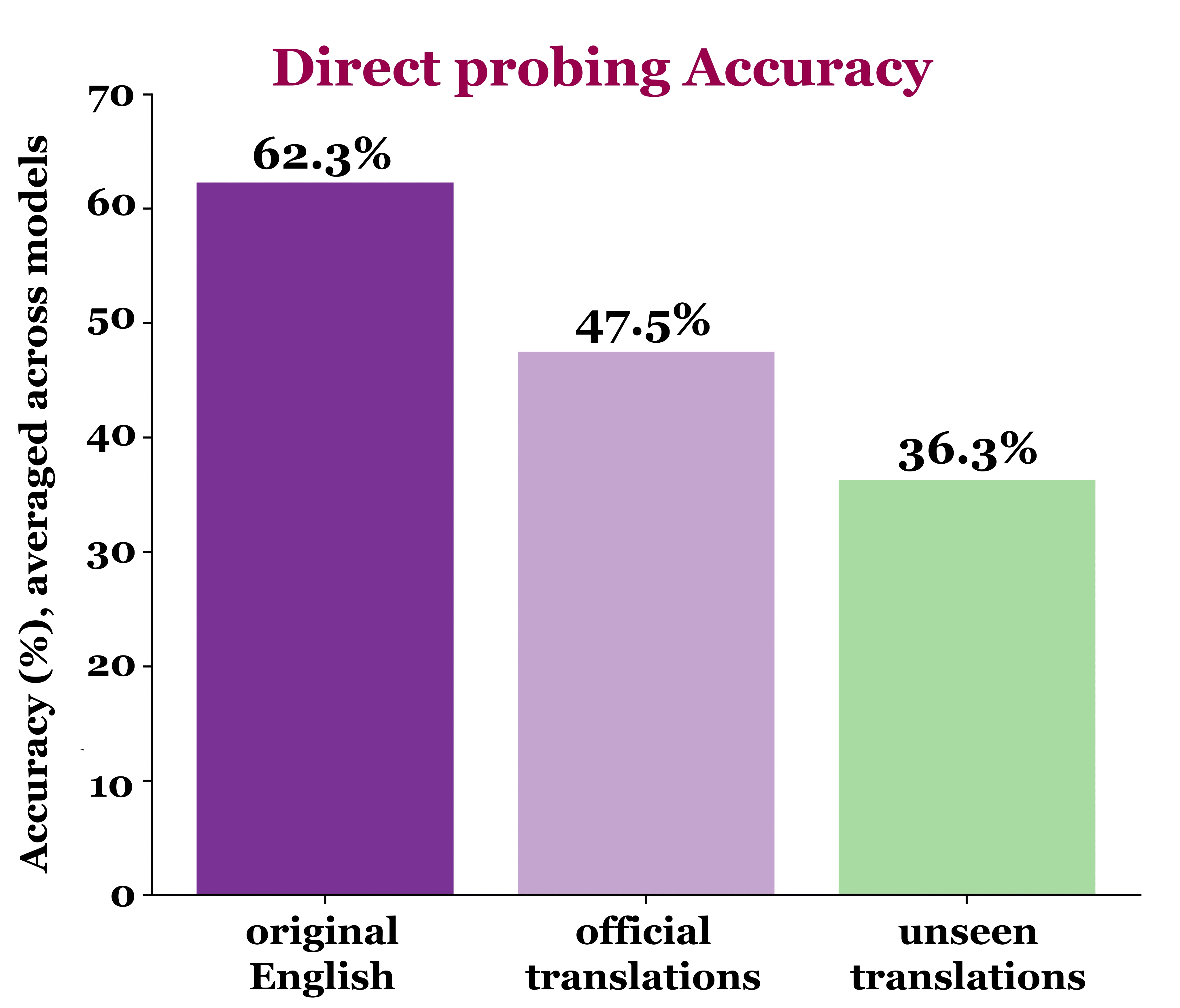
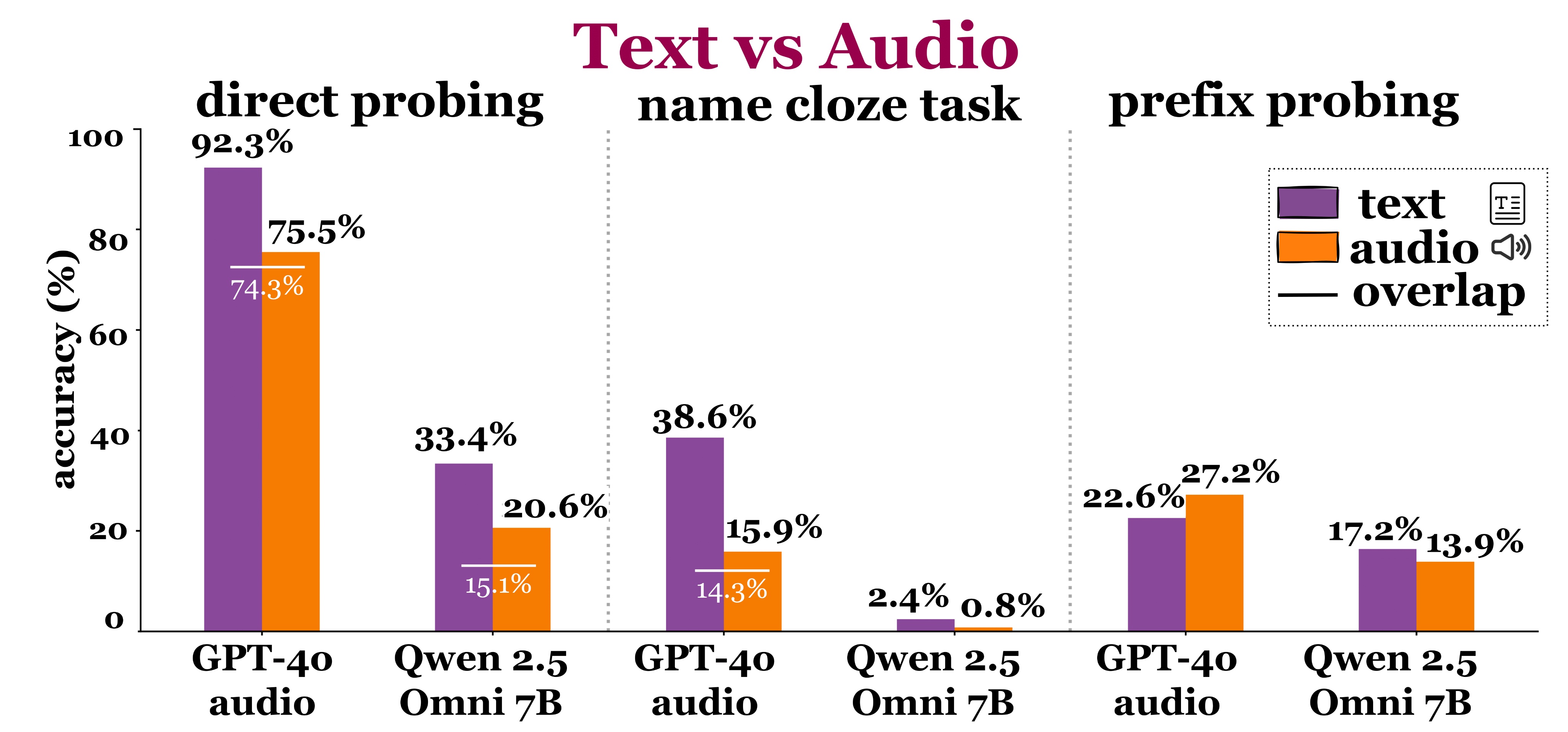
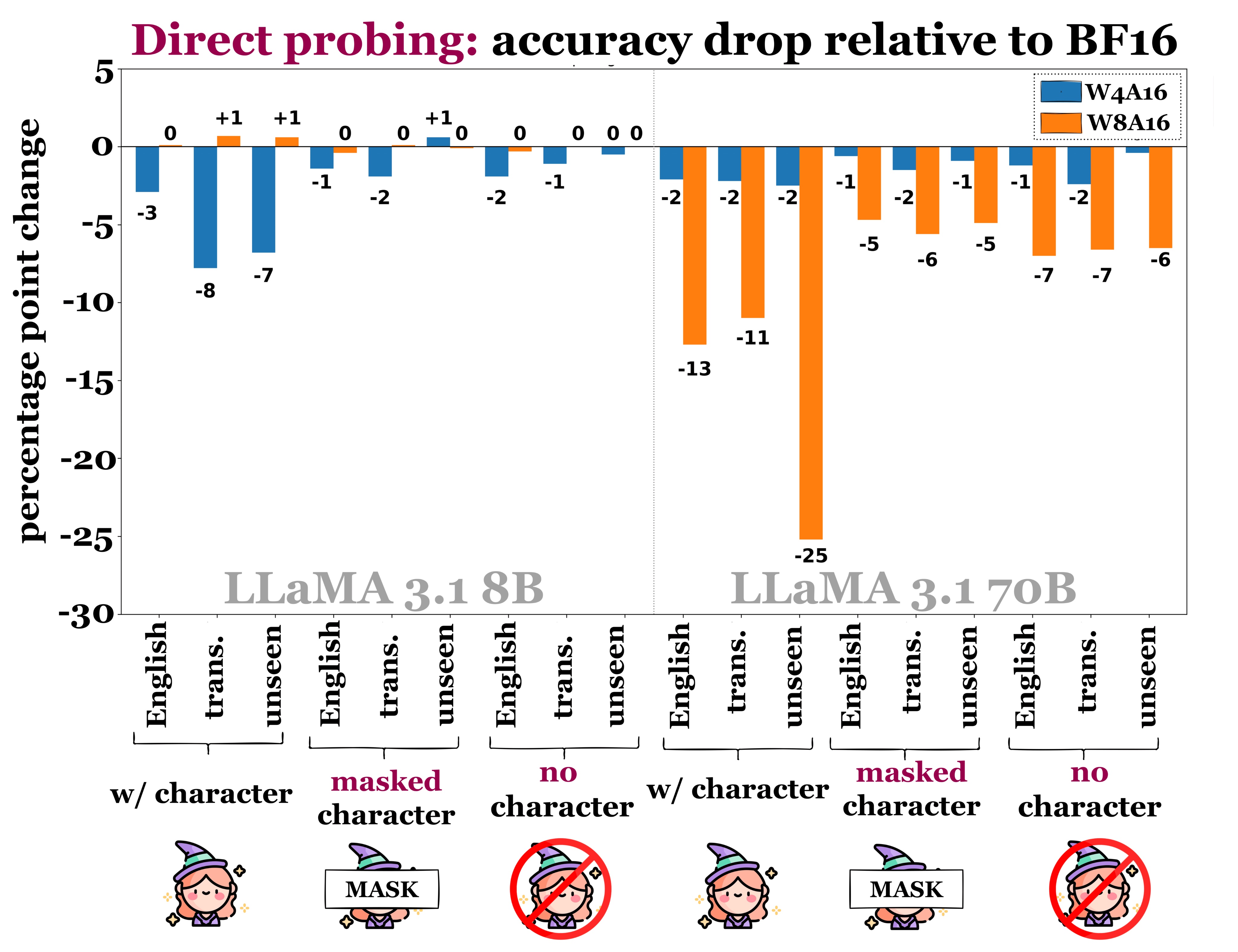
Experiments
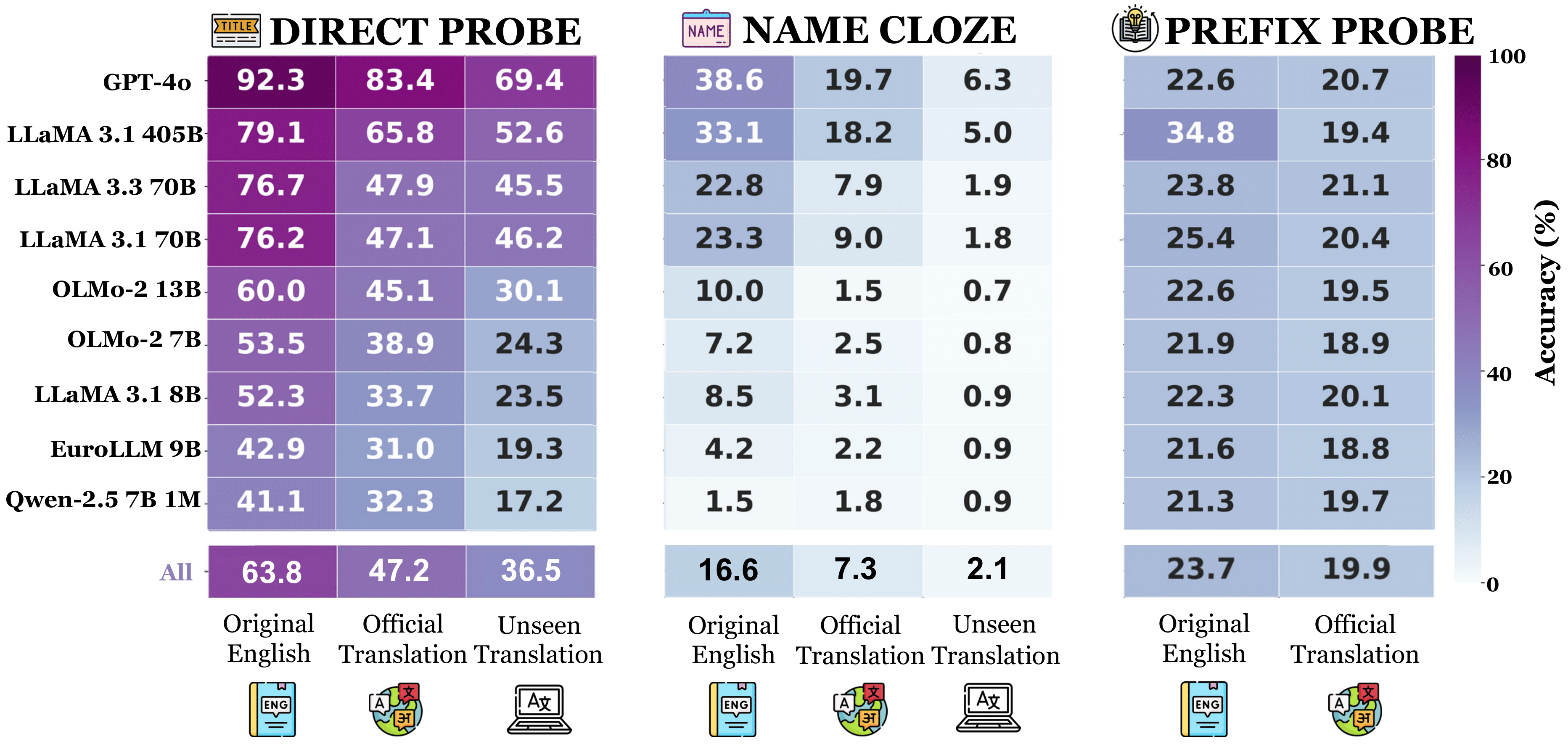

We probe LLMs to identify books and authors across languages, predict masked character names, and generate continuations via memorization as knowledge accquisiton.
There is non-zero accuracy across all tasks and languages, even for low-resource languages. This suggests that LLMs do exhibit cross-lingual knowledge transfer.
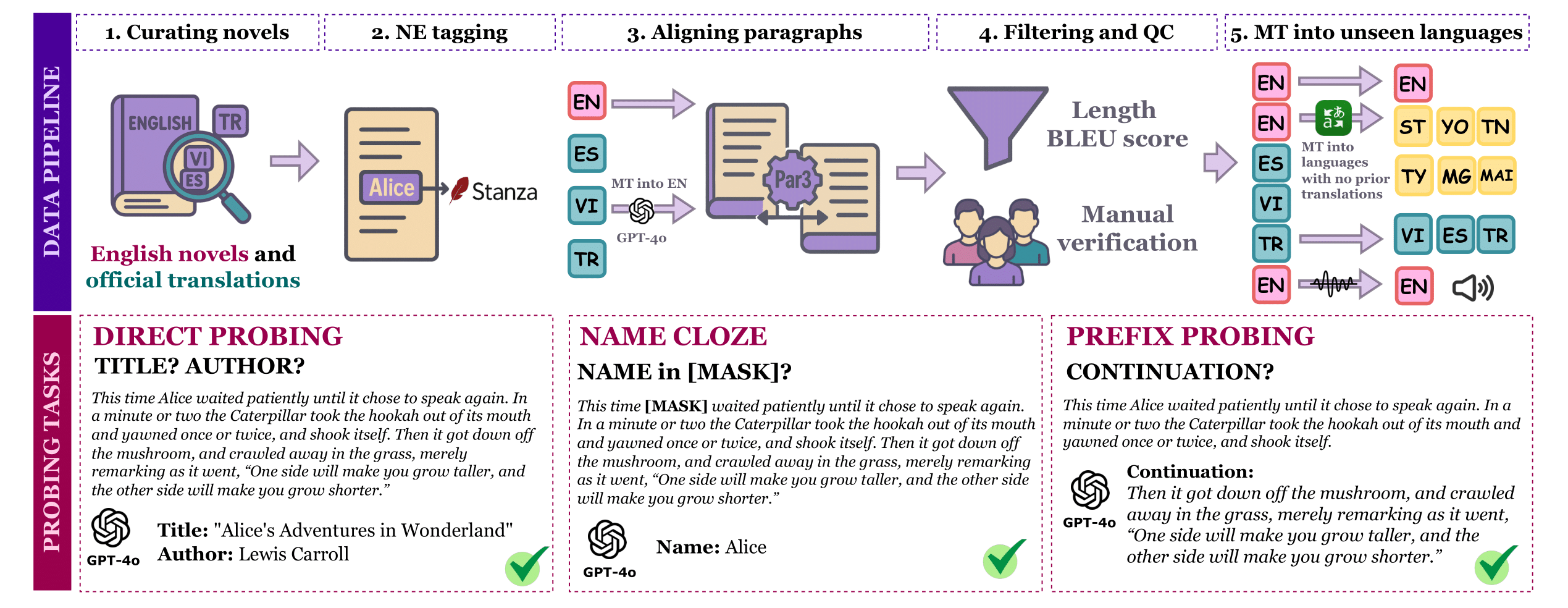
Constructing 🦉 OWL

Note: Unseen translations are likely to be unseen as they are newly created translations for books which to the best of our knowledge did not have exisitng translations in these low resource languages.
If you'd like to construct your own dataset from our pipeline, you can see our code here.
In the future, we plan to release a Python library which will allow you to construct your own multilingual & multimodal OWL dataset from any text corpus.
Acknowledgements
We'd like to thank our ERSP advisor, Mohit Iyyer, and mentors Marzena Karpinska and Chau Minh Pham for their guidance and support. We'd also like to thank the UMass Natural Language Processing Group for their feedback and funding.